
#embeddings



Как создать ИИ Телеграм-бот с векторной памятью на Qdrant
Идея создания этого пет-проекта возникла из желания написать собственного ИИ-агента. Я сформулировал для себя минимальные технические требования: агент должен иметь несколько состояний, уметь запускать тулзы и использовать RAG для поиска ответов на вопросы. В итоге возникла идея написать персонального телеграм-ИИ-бота, который умеет запоминать нужную мне информацию, и когда мне надо — я могу его спросить, что он запомнил. Что-то вроде блокнота, только это будет ИИ-блокнот, который умеет отвечать на вопросы. В дополнение я решил добавить в него функцию, чтобы он мог запускать команды на сервере — причём команды, описанные человеческим языком, он будет переводить в команды для терминала. Изначально я думал использовать LangChain. Очень хороший инструмент — позволяет подключать векторные базы данных, использовать различные LLM как для инференса, так и для эмбеддинга, а также описывать логику работы агента через граф состояний. Можно вызывать уже готовые тулзы. В целом, на первый взгляд всё выглядит удобно и просто, особенно когда смотришь типовые и несложные примеры. Но, покопавшись немного глубже, мне показалось, что затраты на изучение этого фреймворка не оправдывают себя. Проще напрямую вызывать LLM, эмбеддинги и Qdrant через REST API. А логику работы агента описать в коде через enum, описывающий состояния, и делать match по этим состояниям. К тому же LangChain изначально написан на Python. Я хотел бы писать на Rust, а использовать Rust-версию LangChain — сомнительное удовольствие, которое обычно упирается в самый неподходящий момент: что-то ещё не было переписано на Rust.


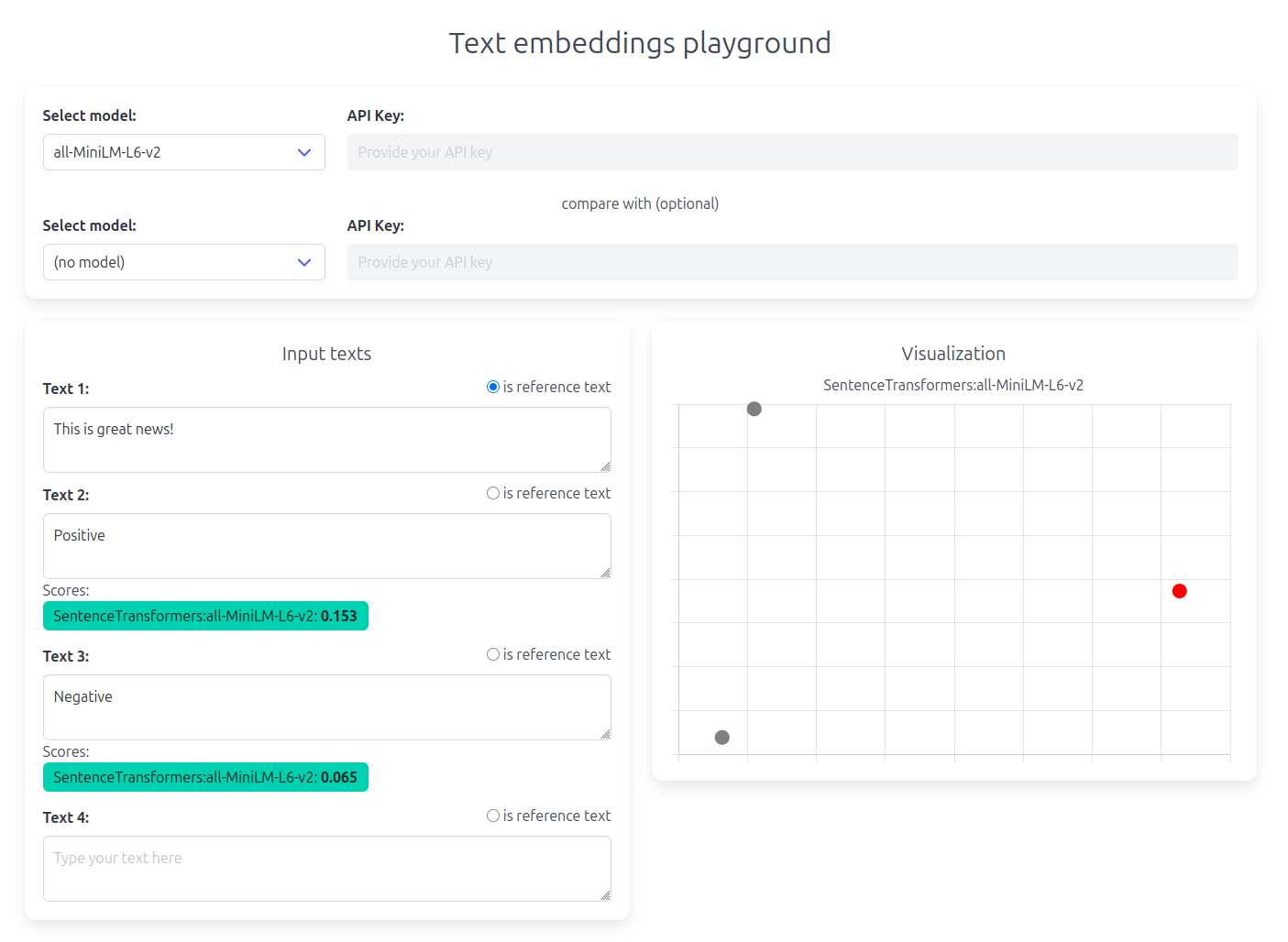
Big update to my Embeddings Playground. I added support for the first free-to-use embedding model: "all-MiniLM-L6-v2" from Sentence transformers (https://www.sbert.net/).
Try the Embeddings playground here: https://embeddings.svana.name

Nomic Embed Code. #embeddings specifically for code from Nomic.
https://www.nomic.ai/blog/posts/introducing-state-of-the-art-nomic-embed-code

We are very happy that our colleage @GenAsefa has contributed the chapter on "Neurosymbolic Methods for Dynamic Knowledge Graphs" for the newly published Handbook on Neurosymbolic AI and Knowledge Graphs together with Mehwish Alam and Pierre-Henri Paris.
Handbook: https://ebooks.iospress.nl/doi/10.3233/FAIA400
our own chapter on arxive: https://arxiv.org/abs/2409.04572


Should you use OpenAI (or other closed-source) embeddings?
1. Try the lightest embedding model first
2. If it doesn’t work, try a beefier model and do a blind comparison
3. If you are already using a relatively large model, only then try some blind test against a proprietary model. If you really find it that the closed-source model is better for your application, then go for it.
Paraphrased from https://iamnotarobot.substack.com/p/should-you-use-openais-embeddings

Poster from our colleague @epoz from UGent-IMEC Linked Data & Solid course. "Exploding Mittens - Getting to grips with huge SKOS datasets" on semantic embeddings enhanced SPARQL queries for ICONCLASS data.
Congrats for the 'best poster' award ;-)
poster: https://zenodo.org/records/14887544
iconclass on GitHub: https://github.com/iconclass
#rdf2vec #bert #llm #embeddings #iconclass #semanticweb #lod #linkeddata #knowledgegraphs #dh @nfdi4culture @fiz_karlsruhe #iconclass


 New Video Alert!
New Video Alert!
Explore advanced image generation with Stable Diffusion in our latest "GenAI's Lamp" tutorial. Learn how to use #Embeddings and #LoRAs to create stunning visuals.
Watch now! 
 https://youtu.be/mZ6eVw8-MM8
https://youtu.be/mZ6eVw8-MM8

I wrote a post about using #embeddings to map out speeches from the Swedish parliament. Would love to hear your thoughts.
https://noterat.github.io/posts/noteringar/202407301845.html

Is there a consensus process or good paper on state of the art on using #embeddings & #LLM to do the kinds of things that were being done with topic models? I imagine for tasks with pre-defined classifications, prompts are sufficient, but any recommendations for identifying latent classes? After reading the paper below I think I'll want to use local models. #machinelearning https://drive.google.com/file/d/1wNDIkMZfAGoh4Oaojrgll9SPg3eT-YXz/view

Major Update for Vector Search in SQLite
 #SQLite-vec v0.1.6 introduces powerful new features:
#SQLite-vec v0.1.6 introduces powerful new features:
• Added support for #metadata columns enabling WHERE clause filtering in #KNN queries
• Implemented partition keys for 3x faster selective queries
• New auxiliary columns for efficient unindexed data storage
• Compatible with #embeddings from any provider
 Key improvements:
Key improvements:
• Store non-vector data like user_id and timestamps
• Filter searches using metadata constraints
• Optimize query performance through smart partitioning
• Enhanced data organization with auxiliary columns
 Performance focus:
Performance focus:
• Partition keys reduce search space significantly
• Metadata filtering streamlines result selection
• Auxiliary columns minimize JOIN operations
• Binary quantization options for speed optimization
 #Database integration:
#Database integration:
• Supports boolean, integer, float & text values
• Works with standard SQL queries
• Enables complex search combinations
• Maintains data consistency
Source: https://alexgarcia.xyz/blog/2024/sqlite-vec-metadata-release/index.html

 Great read on binary vector embeddings & why they are so impressive.
Great read on binary vector embeddings & why they are so impressive.
In short, they can retain 95+% retrieval accuracy with 32x compression and ~25x retrieval speedup. 
 https://emschwartz.me/binary-vector-embeddings-are-so-cool/
https://emschwartz.me/binary-vector-embeddings-are-so-cool/
 Evan Schwartz
Evan Schwartz
#ai #appreciation #LLM #embeddings #scour #search

 Sentiamo sempre più spesso parlare di #embeddings: di cosa si tratta, come si generano, e come possono essere utili nei flussi operativi? Una spiegazione semplice, con alcuni esempi di utilizzo: https://www.alessiopomaro.it/embeddings-cosa-sono-esempi/. Facciamo anche alcune importanti riflessioni sull'importanza della consapevolezza di questi sistemi per ottenere performance.
Sentiamo sempre più spesso parlare di #embeddings: di cosa si tratta, come si generano, e come possono essere utili nei flussi operativi? Una spiegazione semplice, con alcuni esempi di utilizzo: https://www.alessiopomaro.it/embeddings-cosa-sono-esempi/. Facciamo anche alcune importanti riflessioni sull'importanza della consapevolezza di questi sistemi per ottenere performance.



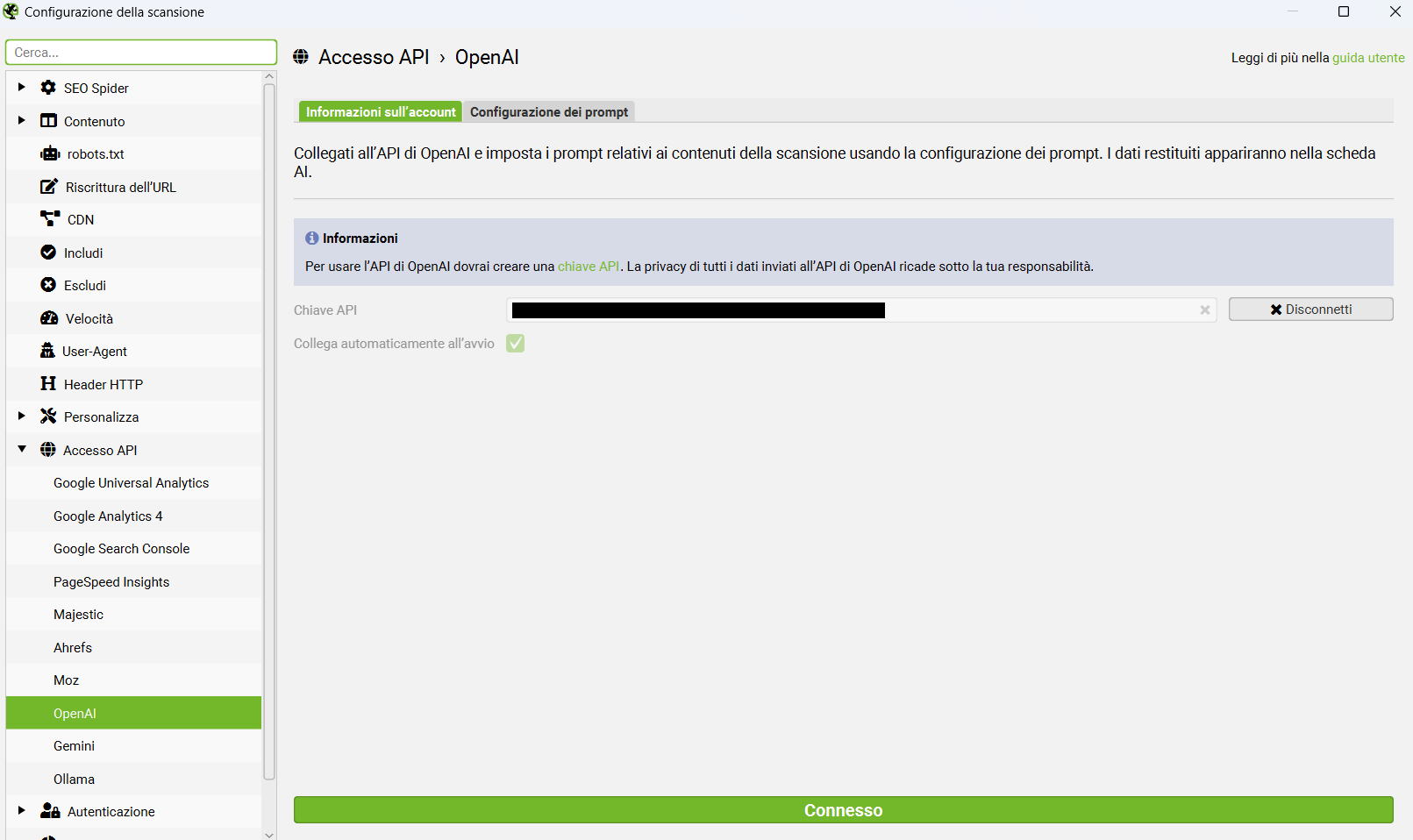
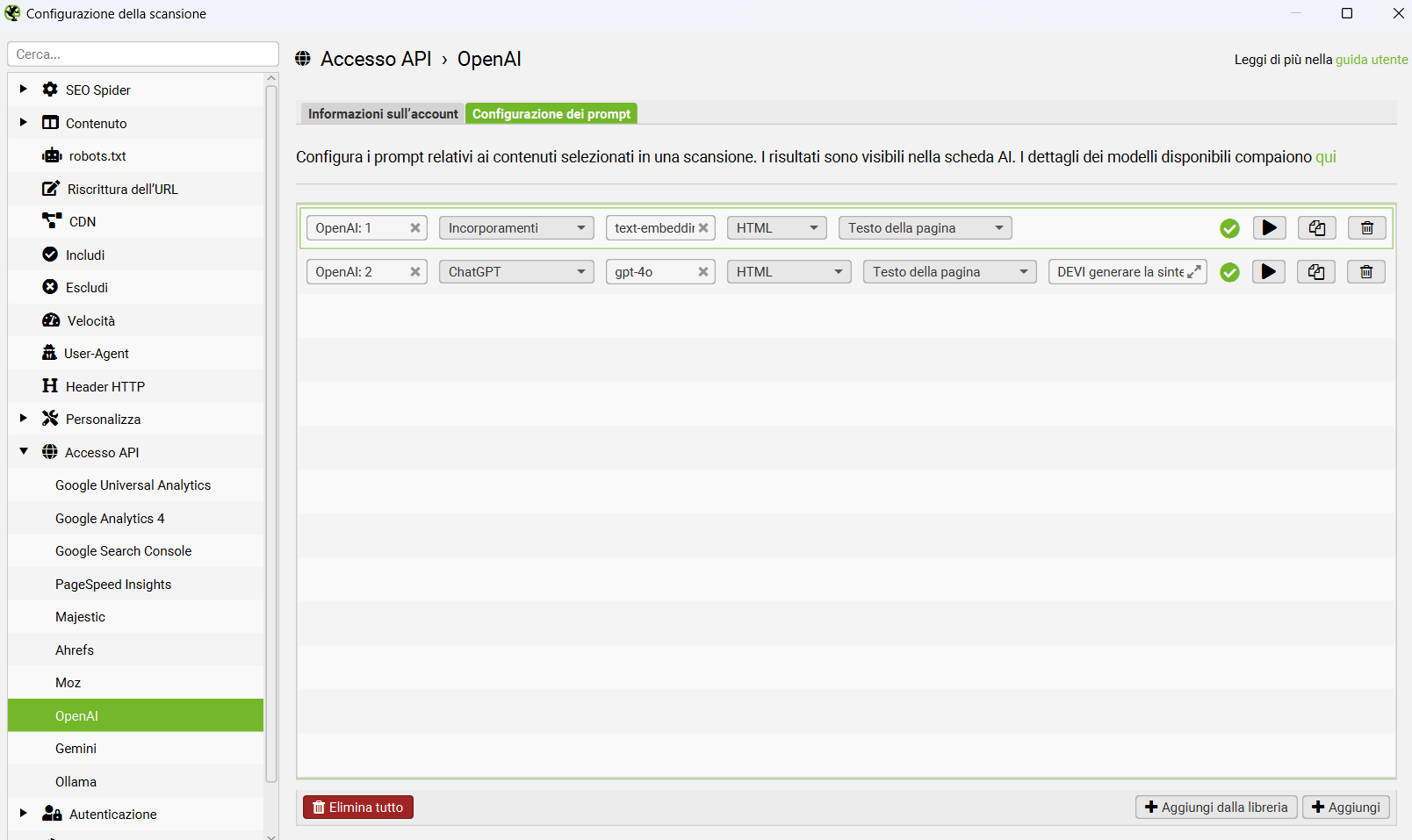
 Screaming Frog introduce le API per l'interfacciamento con i modelli di #OpenAI, #Google e con #Ollama. Lavora sull'HTML salvato in fase di scansione, mentre nella versione precedente si usavano snippet JavaScript personalizzati eseguiti durante il rendering delle pagine.
Screaming Frog introduce le API per l'interfacciamento con i modelli di #OpenAI, #Google e con #Ollama. Lavora sull'HTML salvato in fase di scansione, mentre nella versione precedente si usavano snippet JavaScript personalizzati eseguiti durante il rendering delle pagine.  È possibile generare #embeddings e contenuti con prompt personalizzati su contesti selezionabili (attraverso estrattori predefiniti e custom).
È possibile generare #embeddings e contenuti con prompt personalizzati su contesti selezionabili (attraverso estrattori predefiniti e custom).
#txtai - All-in-one #embeddings database combining vector indexes, graph networks & relational databases
 Key Features:
Key Features:
• Vector search with SQL support, object storage, topic modeling & multimodal indexing for text, documents, audio, images & video
• Built-in #RAG capabilities with citation support & autonomous #AI agents for complex problem-solving
• #LLM orchestration supporting multiple frameworks including #HuggingFace, #OpenAI & AWS Bedrock
• Seamless integration with #Python 3.9+, built on #FastAPI & Sentence Transformers
 Technical Highlights:
Technical Highlights:
• Supports multiple programming languages through API bindings (#JavaScript, #Java, #Rust, #Go)
• Easy deployment: run locally or scale with container orchestration
• #opensource under Apache 2.0 license
• Minimal setup: installation via pip or Docker
Use Cases:
• Semantic search applications
• Knowledge base construction
• Multi-model workflows
• Speech-to-speech processing
• Document analysis & summarization
Learn more: https://github.com/neuml/txtai
Ieri, al Festival Biblico Tech, la protagonista è stata l'#AI, ma soprattutto la riflessione e lo spirito critico.  Con una grande conduzione di Massimo Cerofolini e Roberta Rocelli, e con compagni di viaggio d'eccezione. Porto a casa nuovi stimoli, nuovi pensieri, e, da buon nerd, un test da mettere in atto sugli #embeddings e la valutazione dei bias dei #LLM, discusso con Paolo Benanti.
Con una grande conduzione di Massimo Cerofolini e Roberta Rocelli, e con compagni di viaggio d'eccezione. Porto a casa nuovi stimoli, nuovi pensieri, e, da buon nerd, un test da mettere in atto sugli #embeddings e la valutazione dei bias dei #LLM, discusso con Paolo Benanti.


Wasn’t this…obvious? 
“Vector Databases Are The Wrong Abstraction”, Timescale (https://www.timescale.com/blog/vector-databases-are-the-wrong-abstraction/).

Brand new #OpenSource tool for #PostgreSQL - pgai Vectorizer - just launched today from #TimescaleDB! Manage #embeddings with just one #SQL command to keep embeddings in sync with your data in a far easier fashion.
Learn more on the #GitHub repository here: https://github.com/timescale/pgai/blob/main/docs/vectorizer.md
 Domani, all'Advanced SEO Tool vedremo una pillola tecnica dal titolo "Embeddings e SEO: è QUASI magia". È possibile rimuovere quel "QUASI"? Secondo me sì.. con la consapevolezza di questi strumenti, che proveremo ad acquisire.
Domani, all'Advanced SEO Tool vedremo una pillola tecnica dal titolo "Embeddings e SEO: è QUASI magia". È possibile rimuovere quel "QUASI"? Secondo me sì.. con la consapevolezza di questi strumenti, che proveremo ad acquisire.  Vedremo esempi pratici di utilizzo, test e considerazioni. Per poi scoprire che non si tratta di "magia"!
Vedremo esempi pratici di utilizzo, test e considerazioni. Per poi scoprire che non si tratta di "magia"!
