

TIL the Tranco domain ranking data is available as a public data source in BigQuery - so you can do e.g.:
```
select
domain,
rank
from `tranco.daily.daily`
where date = date_sub(current_date(), interval 1 day)
and domain in ("bbc.co.uk", "bbc.com")
order by rank asc
```
https://tranco-list.eu
tranco-list.euA research-oriented top sites ranking hardened against manipulation - Tranco



 Using
Using  Data wrangled with
Data wrangled with 



 "Map of Python" is the digital dabbling of a cartographer, lost in the vast jungle of 500,000+
"Map of Python" is the digital dabbling of a cartographer, lost in the vast jungle of 500,000+ 
 But hey, at least there's
But hey, at least there's 


 No more manually cross-referencing dbt docs from dev and prod
No more manually cross-referencing dbt docs from dev and prod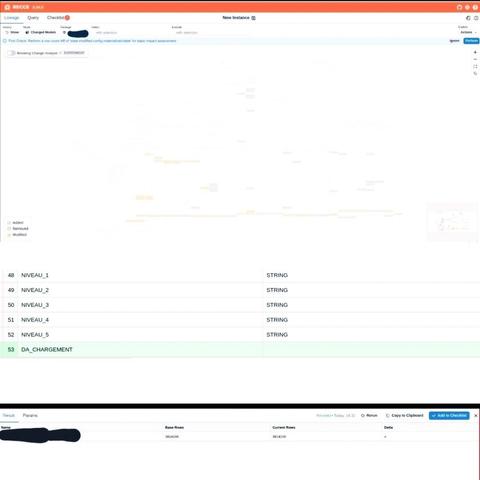

 Exploring dbt for Data Transformation
Exploring dbt for Data Transformation



 Qiita - 人気の記事
Qiita - 人気の記事 


 For this week's module, we used Google's BigQuery to read Parquet files from a GCS bucket, and compare querying on regular, external and partitioned/clustered tables.
For this week's module, we used Google's BigQuery to read Parquet files from a GCS bucket, and compare querying on regular, external and partitioned/clustered tables. My answers to this module:
My answers to this module: 





